WebGPU와 Compute Shader - Image Blur 알고리즘 살펴보기
2021.08.15WebGPU는 WebGL을 이을 차세대 웹 그래픽스 기술입니다. 특히 기본 렌더링 파이프라인에 대한 shader 프로그래밍만 지원하는 WebGL과 달리, compute shader API를 지원하여 GPU에서 다양한 작업을 수행할 수 있습니다.
Compute Shader를 활용한 image blur
마치 vertex shader, fragment shader에서 파이프라인이 각 vertex, pixel에 대해 병렬적으로 GPU에서 실행되듯이, compute shader는 지정한 연산을 병렬적으로 실행합니다. 다만 input, output buffer를 자유롭게 지정할 수 있기 때문에 고정된 렌더링 파이프라인에서 벗어나 더 다양한 작업에 활용할 수 있습니다.
WebGPU의 compute shader로 인한 가능성을 보여주는 대표적인 예시로 image blurring을 짧게 살펴보겠습니다. 2019년 Google I/O에서도 나왔는데요, compute shader의 shared memory 개념을 활용하여 효율적으로 계산을 수행합니다.
Image blur 예시는 playground 에서 볼 수 있습니다. (Chrome의 Canary 버전을 설치하고
--enable-unsafe-webpuflag를 켠 상태에서 실행해 볼 수 있습니다.)
기본적인 image blur 알고리즘
이 알고리즘의 핵심 아이디어는 중복으로 실행되는 텍스쳐 샘플링이 너무 많다는 것입니다. 크기 N의 box filter를 적용할 경우, 각 픽셀마다 자신을 중심으로 N개 픽셀에서 텍스쳐의 값을 읽어와야 합니다. X방향으로 box filter를 적용하는 알고리즘을 코드로 나타내면 다음과 같습니다.
// var position : vec2<u32> = 현재 픽셀 위치
// var N : u32 = 필터 크기
// var inputTex : texture_2d<f32> = box filter를 적용할 텍스쳐
// var outputTex : texture_2d<f32> = 결과를 저장할 텍스쳐
var outValue : vec3<f32> = vec3<f32>(0.0, 0.0, 0.0);
var centerOffset : u32 = (N - 1u) / 2u;
for (var offset : u32 = 0u; f < N; f = f + 1u) {
var i : vec2<u32> = vec2<u32>(position.x + offset - centerOffset, position.y);
outValue = outValue + (1.0 / f32(N)) * textureSample(inputTex, samp, i).rgb;
}
textureStore(outputTex, position, vec4<f32>(outValue, 1.0));
여기에서 textureSample이 실행되는 인덱스인 i를 유심히 살펴봅시다. 각 position마다 자신을 중심으로 한 N개 픽셀이 바로 i가 됩니다. 따라서, 같은 i에 대해 여러 번 textureSample이 일어나게 됩니다!

Compute shader의 shared memory를 활용하여 중복 샘플링을 최소화하는 것이 개선된 알고리즘의 핵심입니다.
개선된 image blur 알고리즘
다음은 image blur 연산을 효율적으로 수행하는 compute shader입니다. (위 예시의 소스 코드에서 발췌했습니다.)
[[block]] struct Params {
filterDim : u32;
blockDim : u32;
};
[[group(0), binding(0)]] var samp : sampler;
[[group(0), binding(1)]] var<uniform> params : Params;
[[group(1), binding(1)]] var inputTex : texture_2d<f32>;
[[group(1), binding(2)]] var outputTex : texture_storage_2d<rgba8unorm, write>;
[[block]] struct Flip {
value : u32;
};
[[group(1), binding(3)]] var<uniform> flip : Flip;
// This shader blurs the input texture in one direction, depending on whether
// |flip.value| is 0 or 1.
// It does so by running (128 / 4) threads per workgroup to load 128
// texels into 4 rows of shared memory. Each thread loads a
// 4 x 4 block of texels to take advantage of the texture sampling
// hardware.
// Then, each thread computes the blur result by averaging the adjacent texel values
// in shared memory.
// Because we're operating on a subset of the texture, we cannot compute all of the
// results since not all of the neighbors are available in shared memory.
// Specifically, with 128 x 128 tiles, we can only compute and write out
// square blocks of size 128 - (filterSize - 1). We compute the number of blocks
// needed in Javascript and dispatch that amount.
var<workgroup> tile : array<array<vec3<f32>, 128>, 4>;
[[stage(compute), workgroup_size(32, 1, 1)]]
fn main(
[[builtin(workgroup_id)]] WorkGroupID : vec3<u32>,
[[builtin(local_invocation_id)]] LocalInvocationID : vec3<u32>
) {
let filterOffset : u32 = (params.filterDim - 1u) / 2u;
let dims : vec2<i32> = textureDimensions(inputTex, 0);
let baseIndex = vec2<i32>(
WorkGroupID.xy * vec2<u32>(params.blockDim, 4u) +
LocalInvocationID.xy * vec2<u32>(4u, 1u)
) - vec2<i32>(i32(filterOffset), 0);
for (var r : u32 = 0u; r < 4u; r = r + 1u) {
for (var c : u32 = 0u; c < 4u; c = c + 1u) {
var loadIndex = baseIndex + vec2<i32>(i32(c), i32(r));
if (flip.value != 0u) {
loadIndex = loadIndex.yx;
}
tile[r][4u * LocalInvocationID.x + c] =
textureSampleLevel(inputTex, samp,
(vec2<f32>(loadIndex) + vec2<f32>(0.25, 0.25)) / vec2<f32>(dims), 0.0).rgb;
}
}
workgroupBarrier();
for (var r : u32 = 0u; r < 4u; r = r + 1u) {
for (var c : u32 = 0u; c < 4u; c = c + 1u) {
var writeIndex = baseIndex + vec2<i32>(i32(c), i32(r));
if (flip.value != 0u) {
writeIndex = writeIndex.yx;
}
let center : u32 = 4u * LocalInvocationID.x + c;
if (center >= filterOffset &&
center < 128u - filterOffset &&
all(writeIndex < dims)) {
var acc : vec3<f32> = vec3<f32>(0.0, 0.0, 0.0);
for (var f : u32 = 0u; f < params.filterDim; f = f + 1u) {
var i : u32 = center + f - filterOffset;
acc = acc + (1.0 / f32(params.filterDim)) * tile[r][i];
}
textureStore(outputTex, writeIndex, vec4<f32>(acc, 1.0));
}
}
}
}
코드를 차례대로 살펴보면,
[[group(0), binding(0)]] var samp : sampler;
[[group(0), binding(1)]] var<uniform> params : Params;
[[group(1), binding(1)]] var inputTex : texture_2d<f32>;
[[group(1), binding(2)]] var outputTex : texture_storage_2d<rgba8unorm, write>;
- shader에서 사용할 buffer가 정의되어 있습니다. 이 shader의 목표는
inputTex에 들어있는 이미지에 box filter를 적용한 결과를 계산하여outputTex에 저장하는 것입니다.
[[group(1), binding(3)]] var<uniform> flip : Flip;
- Box filter를 적용할 때, 가로 방향으로 한 번 적용하고, 세로 방향으로 한 번 더 적용하여 계산합니다. (Box filter 계산 시 자주 사용되는 방법입니다. 원래 크기 NxN의 필터라면 픽셀 하나당
N^2번의 sampling이 필요하다고 생각할 수 있습니다. 그러나 이 방법으로 하면2N번의 sampling으로 계산이 가능합니다.) 이 방향을 지정하는 flag입니다.
var<workgroup> tile : array<array<vec3<f32>, 128>, 4>;
tile은 병렬로 돌아가는 compute shader의 invocation (이를 workgroup 이라고 합니다) 에서 모두 접근할 수 있고, 서로 공유하는 메모리입니다. (var<workgroup>에서workgroup이라는 storage class 키워드로부터 알 수 있습니다.)tile은 workgroup 내에서 공유하기 때문에tile을 활용하여inputTex에 대한 sampling 횟수를 줄이는 것이 알고리즘에서 핵심적인 부분입니다.
[[stage(compute), workgroup_size(32, 1, 1)]]
fn main(
[[builtin(workgroup_id)]] WorkGroupID : vec3<u32>,
[[builtin(local_invocation_id)]] LocalInvocationID : vec3<u32>
) {
이 부분에 대해서 더 궁금하다면 WGSL Documentation을 참조하세요.
stage(compute)는 이 함수가 compute shader의 entry point임을 나타냅니다.workgroup_size는 동시에 실행될 compute shader의 개수를 의미하는데요, 여기에서는(32, 1, 1)로 32개의 invocation이 동시에 실행될 것임을 의미합니다.builtin(local_invocation_id)는 현재 invocation의 번호를 나타냅니다. 즉 이 compute shader를 실행시키는 workgroup 내에서LocalInvocationID는(0, 0, 0), ..., (31, 0, 0)의 값을 가집니다.- 이후 compute shader를 실행하라고 명령을 내릴 때는, “workgroup”을 몇 개 실행시킬 지 지정하게 됩니다. 여기에서도 3개 차원으로
(2, 2, 2)처럼 workgroup의 개수를 지정하는데요,builtin(workgroup_id)가 현재 workgroup의 번호가 됩니다. 방금 예시처럼(2, 2, 2)로 실행시켰다면,WorkGroupID는(0, 0, 0), (0, 0, 1), (0, 1, 0), ..., (1, 1, 1)의 값을 가집니다.
정리하자면, 이 compute shader를 (X, Y, Z)개 workgroup에 대해 실행시킨다면
WorkGroupId는(0, 0, 0)부터,(X-1, Y-1, Z-1)까지 각각 하나씩LocalInvocationId는 이 각각의WorkGroupId마다(0, 0, 0)부터(31, 0, 0)까지 각각 하나씩
실행되어, 최종적으로 main이라는 함수는 서로 다른 WorkGroupID와 LocalInvocationID에 대해 여러 번 실행됩니다. 그 중 동시에 실행되는 main 함수는 같은 workgroup에 들어있는 것들입니다. 바로 WorkGroupID는 같고, LocalInvocationID만 서로 다른 invocation들이죠.
let baseIndex = vec2<i32>(
WorkGroupID.xy * vec2<u32>(params.blockDim, 4u) +
LocalInvocationID.xy * vec2<u32>(4u, 1u)
) - vec2<i32>(i32(filterOffset), 0);
for (var r : u32 = 0u; r < 4u; r = r + 1u) {
for (var c : u32 = 0u; c < 4u; c = c + 1u) {
var loadIndex = baseIndex + vec2<i32>(i32(c), i32(r));
if (flip.value != 0u) {
loadIndex = loadIndex.yx;
}
tile[r][4u * LocalInvocationID.x + c] =
textureSampleLevel(inputTex, samp,
(vec2<f32>(loadIndex) + vec2<f32>(0.25, 0.25)) / vec2<f32>(dims), 0.0).rgb;
}
}
이 알고리즘에서 가장 핵심적인 부분입니다.
이 부분을 한마디로 요약하자면, workgroup 내의 invocation들이 서로 협력하여 tile을 채우는 부분입니다.
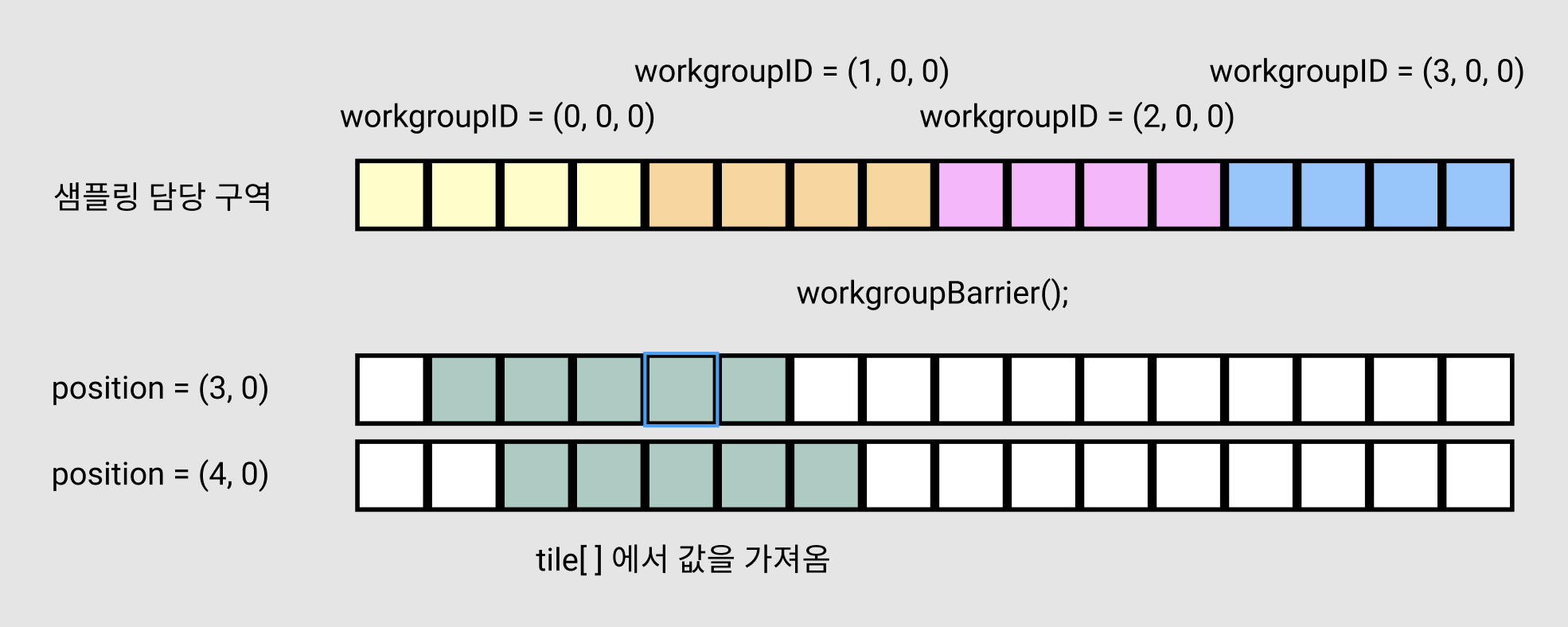
기존 알고리즘은 현재 position에 대한 값을 계산할 때, 옆 position이 무엇을 하는지 관심조차 주지 않기 때문에 중복 연산이 발생했습니다. 하지만 이제는 옆 position에서 텍스쳐를 샘플링한 결과를 알 수 있기 때문에, 서로 중복되지 않도록 영역을 정해 샘플링을 하고, 그 결과를 tile에 저장하여 모두가 볼 수 있도록 하는 것입니다!
- 이 코드에서는 각 invocation이 4x4 구역을 담당하고 있습니다.
r, c에 대한 for loop을 돌면서textureSample을 수행하는데, 이로 인해 전체 이미지를 4x4 구역으로 나누어, 각 invocation이 구역 하나씩 샘플링하여tile배열에 저장하게 됩니다.
LocalInvocationID = (0, 0, 0) -> tile[0 ~ 3][0 ~ 3]을 채움
LocalInvocationID = (1, 0, 0) -> tile[0 ~ 3][4 ~ 7]을 채움
...
LocalInvocationID = (31, 0, 0) -> tile[0 ~ 3][124 ~ 127]을 채움
workgroupBarrier();

workgroupBarrier()다음 줄에 있는 코드는, 모든 invocation에 대해workgroupBarrier()이전 코드가 모두 실행되었음을 보장합니다.- 이 알고리즘에서는
workgroupBarrier()이전에tile에 값을 채우고,workgroupBarrier()이후에tile에 있는 값을 읽어옵니다. 하지만 workgroup 내에 있는 다른 invocation에서 채워야 하는 값을 읽어야 할 수도 있습니다. 코드가 동시에 실행되기 때문에,workgroupBarrier()가 없으면tile에 값이 실제로 채워지기 전에 읽어버리는 상황이 나타나게 됩니다. 따라서workgroupBarrier()를 넣어주어 모든 invocation이 이 위치까지 실행되었고,tile에 값이 모두 올바르게 채워졌음을 확인한 후 다음 단계로 넘어가는 것입니다.
for (var r : u32 = 0u; r < 4u; r = r + 1u) {
for (var c : u32 = 0u; c < 4u; c = c + 1u) {
var writeIndex = baseIndex + vec2<i32>(i32(c), i32(r));
if (flip.value != 0u) {
writeIndex = writeIndex.yx;
}
let center : u32 = 4u * LocalInvocationID.x + c;
if (center >= filterOffset &&
center < 128u - filterOffset &&
all(writeIndex < dims)) {
var acc : vec3<f32> = vec3<f32>(0.0, 0.0, 0.0);
for (var f : u32 = 0u; f < params.filterDim; f = f + 1u) {
var i : u32 = center + f - filterOffset;
acc = acc + (1.0 / f32(params.filterDim)) * tile[r][i];
}
textureStore(outputTex, writeIndex, vec4<f32>(acc, 1.0));
}
}
}
기본 알고리즘에서
outValue = outValue + (1.0 / f32(N)) * textureSample(inputTex, samp, i).rgb;
였던 부분이
acc = acc + (1.0 / f32(params.filterDim)) * tile[r][i];
로 바뀌었다는 사실에 유의하세요. 특히 textureSample이 tile에 대한 array access 연산으로 대체되었습니다. textureSample은 비싼 연산인데, 이 연산은 중복을 최소화하여 꼭 필요한 만큼만 수행합니다. 따라서 개선된 알고리즘이 더 빠르게 동작합니다.