내리막길 (downhill)
2019.11.09문제
당신은 세로 M, 가로 N 크기 격자판의 맨 왼쪽 위에 공을 올려놓았다. 공은 당연하게도 높은 곳에서 더 낮은 곳으로 굴러 떨어진다. 격자판의 높이가 아래 그림처럼 주어졌을 때, 공이 맨 왼쪽 위에서 맨 오른쪽 아래로 굴러갈 수 있는 경우의 수를 구하시오.
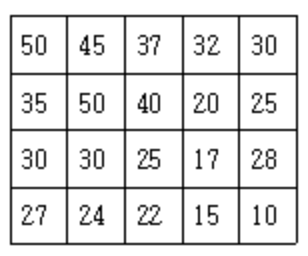
예시
문제에서 주어진 격자판의 경우, 총 3가지 경로가 존재한다.
관찰
2차원 평면 상에서 이동하면서 답을 탐색하는 문제입니다. 따라서 왼쪽 위에서 시작하여, 재귀함수를 이용한 깊이우선탐색(DFS)이나 큐를 이용한 너비우선탐색(BFS)을 통해 오른쪽 아래에 도달하는 방법의 가짓수를 세는 방법을 생각해볼 수 있습니다.
큐와 너비우선탐색 알고리즘을 활용한 풀이만 간단하게 짚고 넘어가겠습니다.
def solve(map):
# 입력 변수:
# map = 격자판의 높이가 들어있는 2차원 리스트
#
# 출력 변수:
# ans = map의 왼쪽 위에서 오른쪽 아래로 도달하는 방법의 가짓수
queue = new Queue()
ans = 0
queue.enqueue((0, 0))
while not queue.empty():
(x, y) = queue.dequeue()
for (adjX, adjY) in <adjacent tiles of (x, y)>:
if map[adjX][adjY] < map[x][y]:
queue.enqueue((adjX, adjY))
# 오른쪽 아래에 도달하면 경우의 수를 1 늘린다.
if (x, y) is (n-1, m-1):
ans = ans + 1
여기에서는 이미 방문한 칸을 다시 방문하지 않는 처리는 하지 않습니다. 왜냐하면, 오른쪽 아래 칸에 도달하는 모든 경우의 수를 세어야 하기 때문입니다. 큐에서 맨 오른쪽 아래 칸 (n-1, m-1)을 만날 때마다 찾은 경우의 수를 1 증가시킵니다.
너비우선탐색 알고리즘의 시간 복잡도는 어떻게 될까요? 격자판이 어떻게 생겼는지에 따라 달라지겠지만, 맨 왼쪽 위에서 맨 오른쪽 아래로 이동하는 경우의 수는 최악의 경우 \(O(2^{N+M})\)가지 정도 됩니다. (오른쪽 아래로 갈수록 높이가 항상 낮아지는 격자판을 생각해 보세요.) 모든 경우의 수를 찾으려면 큐에서 하나씩 경우를 세야 하므로, 알고리즘의 while 루프는 최소한 이 경우의 수만큼 반복됩니다. 따라서, 너비우선탐색 알고리즘의 시간 복잡도는 지수 시간 복잡도인 \(O(2^{N+M})\)임을 알 수 있습니다.
지수 시간 알고리즘은 문제를 빠르게 풀기에는 부족합니다. 중복되는 연산이 어디에서 발생하는지 관찰하여 시간 복잡도를 줄이는 방법에 대해 알아보겠습니다.
큐에서 어떤 칸 (x0, y0) 에 도달한 상황을 생각해 봅시다. 이 상태에서, 너비우선탐색 알고리즘은 내리막길을 통해 이동할 수 있는 칸을 찾으면서 큐에 추가합니다. 그리고 이 과정을 반복하면서 맨 오른쪽 아래 칸 (m-1, n-1) 에 도달하면 경우의 수를 1 늘립니다.
이후 다시 큐에서 (x0, y0) 칸에 도달하면 어떻게 될까요? 바로 앞에서 진행된 과정이 정확하게 동일하게 반복됩니다. 따라서 ”(x0, y0) 칸으로부터 발생할 수 있는 경우의 수”를 기억하고 있다면, 다시 큐로부터 (x0, y0) 칸이 나왔을 때 중복된 연산을 방지하고도 올바른 답을 구할 수 있습니다.
풀이
너비우선탐색과 메모이제이션
관찰을 통해 문제를 효율적으로 풀기 위해서는 메모이제이션을 통해 어떤 칸 (x0, y0) 으로부터 맨 오른쪽 아래 칸에 도달할 수 있는 경우의 수를 저장해 놓는 것이 필요하다는 것을 알 수 있었습니다. 하지만, 너비우선탐색 알고리즘은 이러한 경우에 적용하기 어렵습니다. 그 이유를 예시를 통해 알아보겠습니다.
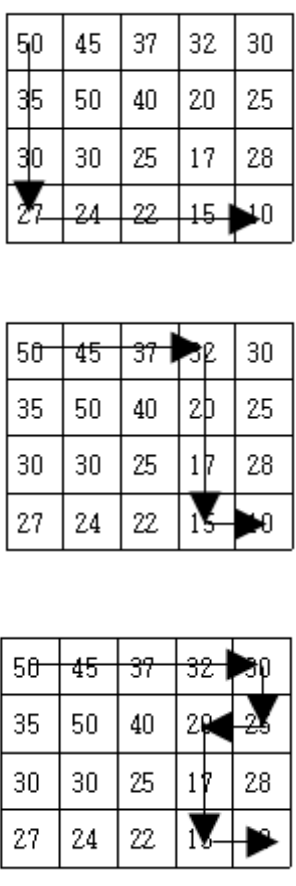
설명의 편의를 위해 오른쪽 아래로 갈수록 높이가 항상 낮아지는 격자를 예시로 사용합니다. 이 경우, 항상 오른쪽이나 아래 방향으로만 이동할 수 있습니다.
너비우선탐색 알고리즘은 시작점 (0, 0)으로부터 가까운 칸부터 큐에 들어갑니다. 따라서 큐에서 차례대로 보게 되는 칸은
(0, 0) -> (0, 1) -> (1, 0) -> (1, 1) -> (1, 1) -> ...
와 같이 나타납니다. 여기에서 (1, 1) 칸이 두 번 나타난다는 사실에 주목하세요. 이는 (0, 1)과 (1, 0) 칸으로부터 모두 (1, 1)칸으로 이동할 수 있고, 같은 칸으로 이동하는 것을 막지 않기 때문입니다. 중복 연산을 하지 않으려면, 두 번째로 (1, 1) 칸에 도달했을 때는 이전에 (1, 1)을 방문한 결과를 이용하여 중복된 연산을 없애야 합니다. 하지만, 우리는 (1, 1) 칸을 이미 큐에서 방문했음에도 불구하고 (1, 1)로부터 맨 오른쪽 아래 칸으로 가는 경우의 수를 아직 알 수 없습니다. 너비우선탐색은 항상 시작점부터 가까운 칸부터 방문하기 때문입니다.
여기에서 너비우선탐색과 깊이우선탐색의 차이점을 알 수 있습니다. 탐색을 깊이우선탐색으로 진행했다면 어떻게 되었을까요? (1, 1) 칸을 2번 방문하게 되는 점은 동일하지만, (1, 1) 칸을 2번째로 방문한 시점은 이미 (1, 1) 칸에서 목적지에 도달할 수 있는 경우의 수를 완벽하게 탐색한 이후입니다. 깊이우선탐색 알고리즘은 어떤 칸에 도달하면 그 칸으로부터 갈 수 있는 모든 경우의 수를 탐색해본 후 다시 돌아가기 때문입니다.
따라서, 너비우선탐색과 메모이제이션을 함께 사용하기는 어렵고, 깊이우선탐색 알고리즘을 사용해야 함을 알 수 있습니다.
깊이우선탐색과 메모이제이션
깊이우선탐색 알고리즘을 통해 문제를 해결하는 알고리즘을 설명한 의사코드입니다.
def dfs(map, x, y):
# 목적지에 도달한 경우, 경우의 수는 1이다.
if (x, y) is (n-1, m-1):
return 1
# 이동할 수 있는 높이가 더 낮은 칸으로 계속 탐색한다.
# 경우의 수는 모든 탐색 결과의 합이다.
sum = 0
for (adjX, adjY) in <adjacent tiles of (x, y)>:
if map[adjX][adjY] < map[x][y]:
sum += dfs(map, adjX, adjY)
return sum
def solve(map):
return dfs(map, 0, 0)
재귀함수에 대해 공부하고 나면, 깊이우선탐색 알고리즘의 탐색 구조가 더 잘 보일 것입니다. 이 함수는 크게 두 부분으로 구성되어 있습니다.
- 가장 기본적인 경우: 이미 목적지
(n-1, m-1)에 도달했을 때. 목적지 칸으로부터 목적지로 갈 수 있는 경우의 수는 1가지. - 더 작은 문제와의 관계
- 여기에서 “더 작은 문제”란, 한 칸을 더 이동한 후 그 칸으로부터 목적지로 갈 수 있는 경우의 수를 뜻합니다. 어떤 칸 A로부터 B와 C로 이동할 수 있었다면, 당연하게도 A로부터 목적지로 갈 수 있는 경우의 수는 B에서 경우의 수와 C에서 경우의 수의 합이 됩니다.
- 따라서 위 의사코드에서는
(x, y)칸으로부터 이동할 수 있는 칸(adjX, adjY)에서 탐색을 진행한 후, 그 결과를 합한 것이 결과가 됩니다.
이 재귀함수에 메모이제이션을 추가하는 것은 간단합니다. (전깃줄 문제에서 다룬 내용을 참고하세요.) 재귀함수의 인자 (x, y)을 통해 함수의 결과 sum을 얻을 수 있는 캐쉬를 만듭니다. dfs(x, y)를 계산해야 할 때, 이미 캐쉬에 결과가 존재하면 그 결과를 리턴하고, 존재하지 않으면 직접 계산한 후 캐쉬에 저장합니다. 이 방식으로 모든 (x, y)에 대해 dfs(x, y)를 단 한 번만 계산하게 됩니다.
cache = {} # 캐쉬 ((x, y)를 dfs(x, y)로 대응시키는 dictionary)
def dfs(map, x, y):
# 캐쉬에 이미 결과가 존재하면, 그 값을 사용한다.
if (x, y) is (n-1, m-1):
return cache[(x, y)]
# 목적지에 도달한 경우, 경우의 수는 1이다.
if (x, y) is (n-1, m-1):
return 1
# 이동할 수 있는 높이가 더 낮은 칸으로 계속 탐색한다.
# 경우의 수는 모든 탐색 결과의 합이다.
sum = 0
for (adjX, adjY) in <adjacent tiles of (x, y)>:
if map[adjX][adjY] < map[x][y]:
sum += dfs(map, adjX, adjY)
cache[(x, y)] = sum # 캐쉬에 값을 저장한다.
return sum
def solve(map):
return dfs(map, 0, 0)
재귀함수와 반복문
재귀함수와 반복문은 서로 동일한 알고리즘을 구현하는 다른 방법입니다. 위의 dfs 함수를 반복문으로 다시 구현해 봅시다.
재귀함수를 반복문으로 옮길때 유의해야 할 점은 값을 참조하는 의존 관계에 유의하여 올바른 순서대로 함수의 값을 계산하는 것입니다. 전깃줄 문제에서 언급했던 피보나치 함수를 다시 예로 들어보겠습니다. f(n) = f(n-1) + f(n-2) 함수를 계산하는 과정에서 n의 함수값은 n-1과 n-2의 함수값에 의존합니다. 따라서, n이 작은 수부터 f(3), f(4), ... 순서대로 계산하면 어떤 f(n)을 계산하더라도 항상 필요한 값을 미리 계산했기 때문에 올바른 답을 얻을 수 있습니다.
이 문제에서는 함수값 간의 의존 관계가 잘 보이지 않습니다. dfs(x, y) 함수값은 이에 인접한 칸인 dfs(x+1, y), dfs(x, y+1), dfs(x-1, y), dfs(x, y-1)에 영향을 받을 수 있습니다. 하지만 칸의 높이에 따라 서로 의존 관계가 달라질 수 있기 때문에 주어진 격자에 상관없이 항상 같은 순서로 계산해 나가는 것은 불가능합니다.
하지만, 공이 항상 높이가 낮은 곳으로 이동한다는 규칙을 이용하면, 높이가 낮은 칸부터 dfs(x, y)를 계산하면 항상 의존 관계에 맞게 진행할 수 있습니다.
def solve(map):
# 칸을 높이(map[i][j]) 순서대로 정렬한다.
tiles = []
for i in range(m):
for j in range(n):
tiles.append((i, j, map[i][j]))
tiles.sort(key=lambda tile: tile[2])
# 차례대로 계산한다.
for (x, y, height) in tiles:
if (x, y) is (m-1, n-1):
dfs[x][y] = 1
else:
for (adjX, adjY) in <adjacent tiles of (x, y)>:
if map[adjX][adjY] < height:
dfs[x][y] += dfs[adjX][adjY]
return dfs[0][0]
반복문으로 구현하고 나면 시간복잡도 분석을 더 쉽게 할 수 있습니다. 맨 처음 NM개의 타일을 높이 순서대로 정렬하는 것은 \(O(NM \log{NM})\)의 시간 복잡도가 필요합니다. 이후 for 루프에서는 NM개의 칸마다 최대 4개의 인접한 칸으로부터 값을 참조하므로, \(O(NM)\)의 시간 복잡도가 필요합니다. 따라서 전체 시간 복잡도는 \(O(NM \log{NM})\)이 됩니다.
입력 및 출력 예제
입력 형식
- 첫 번째 줄에는 지도의 세로 길이
M과 가로 길이N이 공백으로 구분되어 주어진다.(1 <= M, N <= 500) - 다음
M개 줄에 걸쳐 한 줄에N개씩 각 지점의 높이가 공백으로 구분되어 주어진다.(1 <= 높이 <= 10,000)
출력 형식
이동 가능한 경로의 수를 출력한다.
입력 예제 1
4 5
50 45 37 32 30
35 50 40 20 25
30 30 25 17 28
27 24 22 15 10
출력 예제 1
3
원문
여행을 떠난 세준이는 지도를 하나 구하였다. 이 지도는 아래 그림과 같이 직사각형 모양이며 여러 칸으로 나뉘어져 있다. 한 칸은 한 지점을 나타내는데 각 칸에는 그 지점의 높이가 쓰여 있으며, 각 지점 사이의 이동은 지도에서 상하좌우 이웃한 곳끼리만 가능하다.
현재 제일 왼쪽 위 칸이 나타내는 지점에 있는 세준이는 제일 오른쪽 아래 칸이 나타내는 지점으로 가려고 한다. 그런데 가능한 힘을 적게 들이고 싶어 항상 높이가 더 낮은 지점으로만 이동하여 목표 지점까지 가고자 한다. 위와 같은 지도에서는 다음과 같은 세 가지 경로가 가능하다.
지도가 주어질 때 이와 같이 제일 왼쪽 위 지점에서 출발하여 제일 오른쪽 아래 지점까지 항상 내리막길로만 이동하는 경로의 개수를 구하는 프로그램을 작성하시오.
출처
- 한국정보올림피아드, 지역본선 2006 고등부 3번 (내리막길)